Python doesn't enforce naming. You can call a function X or a class my_thing and the interpreter won't care. What you're agreeing to when you write Python is to follow PEP 8, a style guide published in 2001 that became the de facto standard for the entire ecosystem.
The naming conventions are the part everyone needs and the part that trips people up more than any other section. Here's every convention, by identifier type.
Quick reference
| Identifier | Convention | Example |
|---|---|---|
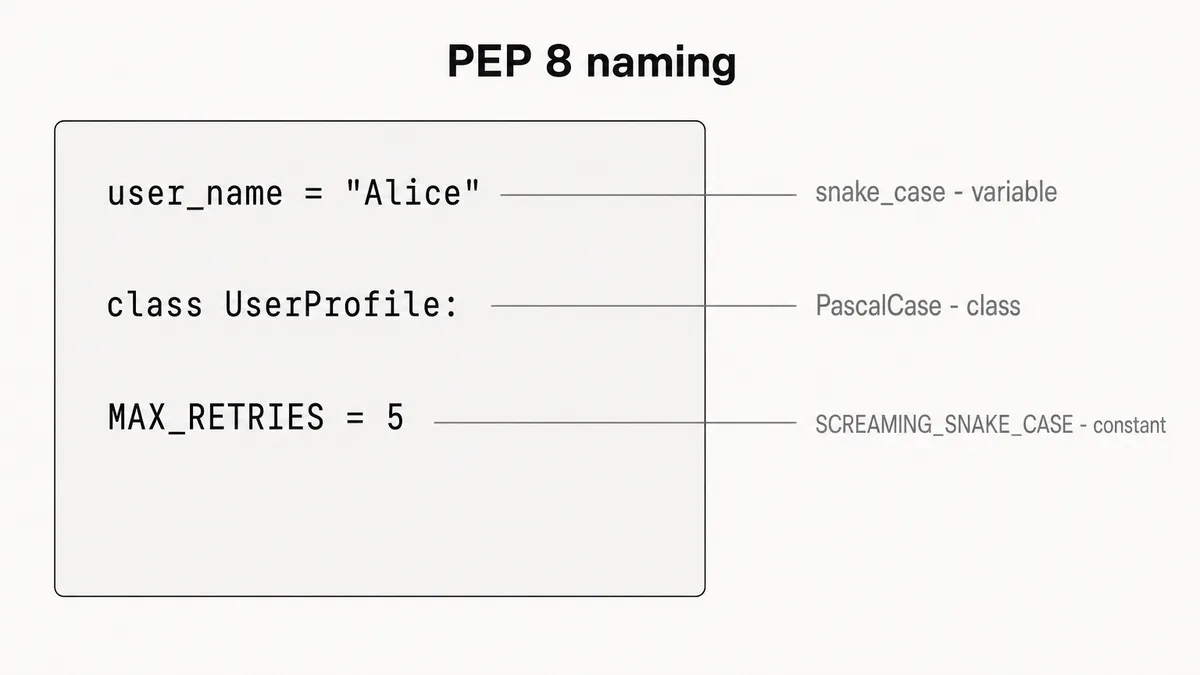
| Variable | snake_case | user_age, file_path |
| Function | snake_case | get_user(), save_file() |
| Class | PascalCase | UserProfile, FileParser |
| Constant | SCREAMING_SNAKE_CASE | MAX_RETRIES, DATABASE_URL |
| Module | lowercase (underscores if needed) | utils, file_parser |
| Package | lowercase, no underscores | mypackage, requests |
| Private attribute | _single_leading_underscore | _internal_id |
| Dunder method | __double_both_sides__ | __init__, __str__ |
This table covers 90% of what you'll name day-to-day. The sections below cover the edge cases and the reasoning behind each rule.
Variables and functions: snake_case
snake_case means all lowercase, words separated by underscores. It applies to both variables and functions.
# Variables
user_name = "Alice"
total_count = 0
is_active = True
# Functions
def get_user(user_id):
pass
def calculate_total(items):
pass
There's a real debate PEP 8 doesn't settle: should function names be verb-first or noun-first?
Verb-first (edit_video, save_file, convert_text) mirrors how people think about actions. When you're writing code, you're thinking "I want to edit a video," so edit_video matches that mental model and reads close to plain English.
Noun-first (video_edit, video_save, video_convert) groups related functions alphabetically. In an IDE with autocomplete, typing video_ shows you every video operation in the module at once. That's genuinely useful when a module has a large surface area.
Neither is wrong. If you're joining an existing project, match what's there. Starting fresh, pick one and stick with it; the inconsistency is the only real mistake.
A few things worth keeping front of mind:
Prefer simple, correctly spelled words. If you have to think about the spelling, the name is too obscure. calculate_discount beats compute_rebate_percentage. Anyone reading your code at 2am can parse the first one immediately.
Skip abbreviations. usr, cnt, tmp save two seconds of typing and cost the next reader two seconds of guessing. The exception is domain-specific abbreviations everyone on the project knows: http, url, mp3, csv.
Don't shadow builtins. Naming a variable list, id, input, or type is valid Python and will produce confusing bugs. Add specificity: user_list, product_id, user_input.
Single letters have one legitimate use: loop counters (i, j, k) and mathematical code where the single-letter name is the actual notation. Everywhere else, name the thing.
If you need to convert a block of names to snake_case format, the snake_case converter handles it in one paste.
Classes: PascalCase
Class names use PascalCase: each word starts with a capital letter, no underscores.
class UserProfile:
pass
class FileParser:
pass
class DatabaseConnectionError(Exception):
pass
The logic is visual: PascalCase immediately signals "this is a class." When you see UserProfile() versus user_profile(), you know without context that the first creates an instance and the second calls a function. That distinction matters when you're scanning unfamiliar code.
Two conventions worth knowing:
Exception classes always end in Error. ValidationError, ConnectionError, TimeoutError, not ValidationException or BadInput. This is consistent across the Python standard library and essentially every major package.
Abstract base classes often use a Mixin suffix. If you're writing a class designed to be mixed into others rather than instantiated directly, LoggingMixin or SerializationMixin signals intent. It's convention, not rule, but widely used.
Constants: SCREAMING_SNAKE_CASE
Constants use all uppercase with underscores. They're defined at module level in Python.
MAX_CONNECTIONS = 10
DEFAULT_TIMEOUT = 30
API_BASE_URL = "https://api.example.com"
Python doesn't enforce immutability here; it's purely a signal to other developers. If something is in SCREAMING_SNAKE_CASE, it means "don't reassign this at runtime."
The practical scope of this convention extends well beyond Python. Environment variables (loaded via os.environ or python-dotenv) use it by default:
DATABASE_URL=postgresql://localhost/mydb
SECRET_KEY=your-secret-key-here
DEBUG=False
MAX_UPLOAD_SIZE_MB=50
Docker Compose, GitHub Actions secrets, and AWS Lambda environment variables all use the same format. SCREAMING_SNAKE_CASE is the standard for configuration values across the entire infrastructure layer, not just Python source files.
If you need to convert a list of constant names to SCREAMING_SNAKE_CASE format, the SCREAMING_SNAKE_CASE converter takes care of it in one paste.
The one mistake people make: using this convention for variables that can actually change. If MAX_RETRIES is computed at startup based on environment config, it's not a constant, so name it accordingly.
Modules and packages
Modules (.py files) should have short, all-lowercase names. Use underscores if they genuinely help readability, but short enough that you usually don't need them.
utils.py
file_parser.py
database.py
auth.py
Packages (directories with __init__.py) follow the same rule but avoid underscores where possible. The reason is import ergonomics: from mypackage import thing is cleaner than from my_package import thing. Small thing, but you type it a lot.
One practical warning: avoid names that shadow standard library modules. Naming your file email.py, json.py, or os.py in a project directory will cause mysterious import failures that take longer than they should to debug.
Private, protected, and dunder naming
This is where most guides are vague. Here's what actually matters.

_single_leading_underscore signals "internal use, proceed with caution." Python doesn't enforce this at all. Another module can still access _my_private_var if it wants to. The underscore is a social convention: "I didn't design this for outside use and I might change it without warning."
One concrete effect: from module import * won't import names with a leading underscore. So if you're building a library and want to control what's in the public API, leading underscores on internal functions and attributes does work as a filter.
__double_leading_underscore triggers name mangling. When you write __attr inside a class definition, Python renames it to _ClassName__attr at the interpreter level. This prevents accidental overriding in subclasses. It's not true private access, but it is a real protection mechanism. Most application code never needs this. It's for library authors building class hierarchies where name collisions in subclasses are a genuine concern.
__dunder__ (double leading AND trailing underscores) is Python's data model. __init__, __str__, __len__, __enter__, __exit__. Never invent your own names in this pattern. Python reserves the format for the language itself, and future versions may assign meaning to whatever you create.
In practice: use _single_leading_underscore for implementation details you don't want as public API. The double variants are edge cases.
Modern Python naming patterns
Most PEP 8 guides were written before Python 3.7. The newer patterns have their own conventions worth knowing:
dataclass fields use snake_case, same as regular attributes, no surprises:
from dataclasses import dataclass
@dataclass
class VideoFile:
file_path: str
duration_seconds: float
is_compressed: bool = False
Enum members use SCREAMING_SNAKE_CASE. They're constants, so they follow the constant convention:
from enum import Enum
class FileFormat(Enum):
MP3 = "mp3"
WAV = "wav"
FLAC = "flac"
TypedDict keys default to snake_case, but this is where cross-stack friction tends to surface, covered in the next section.
Protocol methods use snake_case, same as any method on any class. No special treatment.
The cross-stack naming problem
If you're building a Python backend that talks to a JavaScript frontend, you'll hit this at some point. Python uses snake_case throughout. JSON APIs almost universally use camelCase. A frontend sends {"firstName": "Alice", "userId": 42} and your Python model wants first_name and user_id.
There are a few common ways to handle it:
Pydantic with alias generation is the cleanest approach when using FastAPI:
from pydantic import BaseModel
from pydantic.alias_generators import to_camel
class User(BaseModel):
model_config = {"alias_generator": to_camel, "populate_by_name": True}
first_name: str
user_id: int
Your Python code uses first_name throughout. The API accepts firstName from the client. Both sides stay idiomatic to their own language.
Django REST Framework serializers handle this with field-level aliasing via source=. Same concept, different syntax.
Manual conversion works at small scale: a utility function that converts camelCase keys to snake_case on ingestion and back on serialization. It becomes maintenance overhead as the number of fields grows.
The rule: don't bend your Python naming to match JSON keys. Keep Python code in snake_case and handle the translation at the boundary. That's what serializers and alias generators exist for.
The snake_case converter is useful when you're mapping out which format each field should live in across both sides.
Enforcing naming conventions in your project
Whether you set up a linter depends on what you're building. For a small personal script or a weekend project, probably not worth it. For a web app, a library other people will use, or anything you'll come back to in six months, set it up from the start. Retrofitting linting to an existing codebase is painful in a way that's entirely avoidable.
The tooling is much better than it used to be. Ruff is the current best choice. It replaces flake8, isort, and black in one tool, runs 10–100× faster than the old stack, and configures in pyproject.toml:
[tool.ruff]
line-length = 88
[tool.ruff.lint]
select = ["E", "F", "N"] # N = pep8-naming checks
The N rule set specifically catches naming violations: functions that aren't snake_case, classes that aren't PascalCase, constants that aren't SCREAMING_SNAKE_CASE.
In VS Code, install the Ruff extension and it flags violations inline as you type. JetBrains IDEs have a Python plugin that does the same. Either way, setup is about five minutes.
If you prefer the older stack: flake8 + the pep8-naming plugin catches naming issues, black handles formatting. They work. Ruff is just faster and requires less configuration to get the same coverage.
When PEP 8 naming doesn't apply
Three situations where ignoring these conventions is the right call:
Wrapping external code that uses different conventions. If you're writing a thin wrapper around a C library or a REST client for an API that uses camelCase throughout, renaming everything to snake_case creates more confusion than it removes. Match the underlying interface. Add a comment explaining why if it'll confuse the next person.
Mathematical and scientific code. A function that uses A, B, x, y, n is clearer than one that uses matrix_a, matrix_b, input_vector, output_vector when the single-letter names are the actual mathematical notation. Readability in scientific contexts means matching the notation from the relevant literature, not PEP 8.
Generated code. Don't apply naming conventions to code a tool wrote. Modify the generator configuration if the output style matters to you.
FAQ
What naming convention does Python use for variables?
snake_case: all lowercase, words separated by underscores. user_name, file_path, total_count. Functions use the same convention.
What is the difference between PascalCase and camelCase in Python?
PascalCase capitalises every word including the first (UserProfile, FileParser). camelCase capitalises every word except the first (userProfile, fileParser). Python uses PascalCase for classes and snake_case for everything else. camelCase is the JavaScript convention; it doesn't belong in Python code.
Should I use camelCase in Python? No, with two exceptions: you're maintaining legacy code that already uses it, or you're wrapping a library or API that does. Modern Python is snake_case for variables and functions, PascalCase for classes. camelCase in a Python file is a reliable signal that someone came from JavaScript or Java and didn't adjust.
What is SCREAMING_SNAKE_CASE used for in Python?
Constants defined at module level, plus environment variables across any tool that reads from .env files or the system environment. DATABASE_URL, SECRET_KEY, MAX_RETRIES: anything set once and not reassigned at runtime. Docker Compose, GitHub Actions secrets, and AWS Lambda environment variables all use the same format.
How do I check if my Python code follows PEP 8 naming?
Install Ruff (pip install ruff) and run ruff check . with the N rules enabled. In VS Code, the Ruff extension flags violations as you type. For a quick check without installing anything, pycodestyle.com lets you paste code and see violations immediately.
What does a leading underscore mean in Python?
A single leading underscore (_name) is a convention meaning "internal use; I didn't design this as part of the public API." The interpreter doesn't enforce it. A double leading underscore (__name inside a class) triggers name mangling, renaming the attribute to _ClassName__name to prevent accidental override in subclasses. Most code only needs the single underscore variant.