
If you write Python, you write snake_case. If you write JavaScript, you write camelCase. For most developers, that's where the question ends, and it's the right answer 90% of the time.
The other 10% is where things get interesting: APIs that cross a language boundary, database schemas that outlive any single stack, and teams where half the codebase is Python and the other half is TypeScript.
The short answer: Follow your language's style guide. If you're in Python, that's PEP 8: snake_case everywhere except classes and constants. If you're in JavaScript or TypeScript, camelCase for variables and functions, PascalCase for classes.
The rest of this guide covers the edge cases, the cross-stack problem, and how to enforce whichever convention you choose.
What's the difference between snake_case and camelCase?
snake_case writes all words in lowercase with underscores as separators: user_name, get_order_total, max_retry_count. camelCase joins words without any separator, capitalising each new word after the first: userName, getOrderTotal, maxRetryCount.
Both solve the same problem: programming languages don't allow spaces in identifiers, so you need a way to separate words in a name. Underscores mimic a space; capitalisation marks where one word ends and another begins.
When to use snake_case
Python
PEP 8 mandates snake_case for variables, function names, method names, module names, and file names. Not "recommends." Mandates. If you're writing Python, you're writing snake_case:
def calculate_order_total(line_items, discount_code):
item_count = len(line_items)
subtotal = sum(item.price for item in line_items)
return subtotal - apply_discount(subtotal, discount_code)
Class names use PascalCase (OrderProcessor). Constants use SCREAMING_SNAKE_CASE (MAX_RETRY_COUNT, DATABASE_URL). Everything else is snake_case.
Databases
SQL column names are snake_case regardless of what language the app uses. You'll find user_id, created_at, and order_total in Postgres, MySQL, and SQLite schemas even in JavaScript-first projects. SQL case sensitivity varies by database and collation; underscores don't have that problem.
If your ORM is Django, SQLAlchemy, or ActiveRecord, it maps snake_case column names to object attributes automatically. Trying to use camelCase column names in a SQL database creates friction at every layer: migrations, raw queries, database tools.
Environment variables
DATABASE_URL, API_KEY, NODE_ENV. Every environment variable you've ever used is SCREAMING_SNAKE_CASE. This is a POSIX convention that predates most modern languages, and every platform (Linux, macOS, Windows, Docker, Kubernetes) respects it without question.
When to use camelCase
JavaScript and TypeScript
The ECMAScript specification doesn't mandate casing, but every major JavaScript style guide does. Google's JavaScript Style Guide, Airbnb's, and the TypeScript team's own documentation all land on the same answer: camelCase for variables, functions, and object properties; PascalCase for classes and constructors.
const userName = 'tim';
function getOrderTotal(lineItems, discountCode) {
const itemCount = lineItems.length;
return lineItems.reduce((sum, item) => sum + item.price, 0);
}
class OrderProcessor {
constructor(config) {
this.maxRetries = config.maxRetries;
}
}
TypeScript follows identical rules. ESLint enforces them at lint time via the camelcase rule.
Java and C#
Java uses camelCase for method names and local variables (getUserById, totalAmount). C# splits it: camelCase for private fields, PascalCase for public methods and properties. Both ecosystems have tooling that enforces conventions: Checkstyle for Java, Roslyn analyzers for C#.
JSON API responses
If your API consumers are JavaScript applications (which most web APIs are), camelCase keys work directly without any transformation. {"userName": "tim"} drops straight into a JS object. {"user_name": "tim"} means every consumer has to transform it, and someone eventually forgets.
Language quick-reference
| Language | Variables | Functions | Classes | Constants |
|---|---|---|---|---|
| Python | snake_case | snake_case | PascalCase | SCREAMING_SNAKE_CASE |
| JavaScript | camelCase | camelCase | PascalCase | SCREAMING_SNAKE_CASE |
| TypeScript | camelCase | camelCase | PascalCase | SCREAMING_SNAKE_CASE |
| Java | camelCase | camelCase | PascalCase | SCREAMING_SNAKE_CASE |
| C# | camelCase | PascalCase | PascalCase | PascalCase |
| Ruby | snake_case | snake_case | PascalCase | SCREAMING_SNAKE_CASE |
| Go | camelCase | camelCase | PascalCase | — |
Go exports are worth a note: capitalisation controls visibility. GetUser is exported (public); getUser is unexported (package-private). There's no separate constant convention; visibility is the distinction.
The cross-stack problem
Your FastAPI backend returns {"user_name": "tim", "created_at": "2026-01-15"}. Your React frontend receives it. Now you have snake_case keys sitting in JavaScript code where everything else is camelCase. It's a small mismatch that compounds fast across a large API.
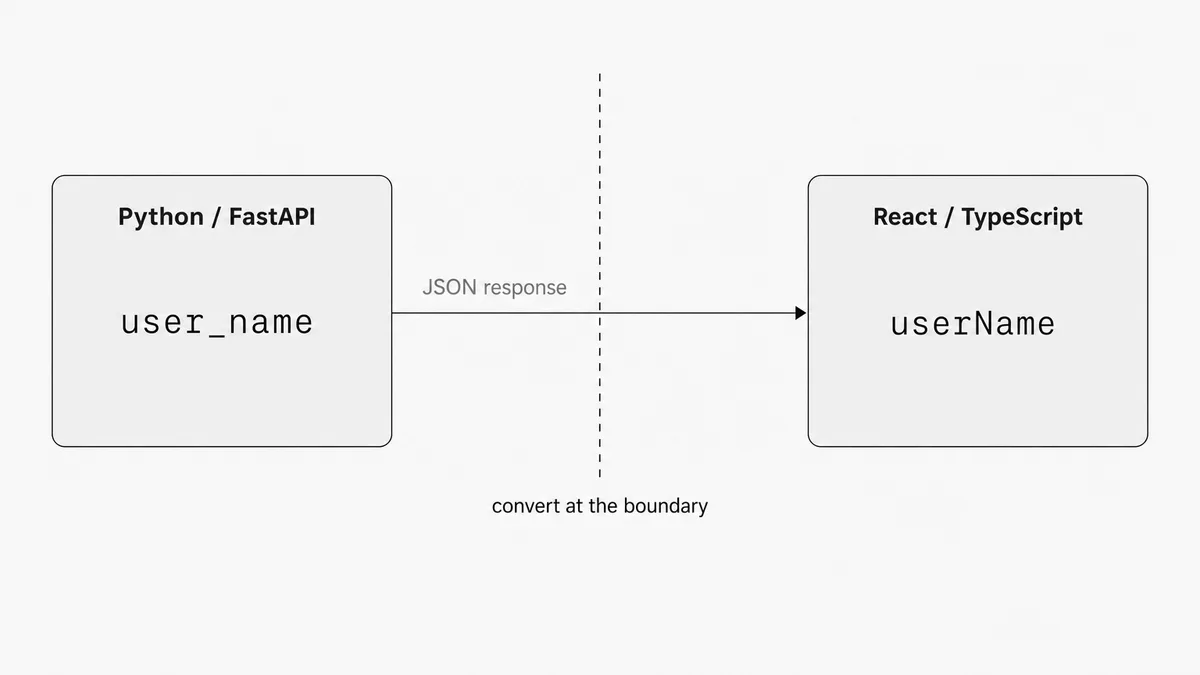
Three practical approaches:
Convert at the serializer. Pydantic (used by FastAPI) lets you set alias_generator = to_camel in a model's model_config. The Python code stays PEP 8-compliant throughout; the outgoing JSON gets camelCase keys. In Django REST Framework, djangorestframework-camel-case handles it at the renderer and parser level. The backend owns the conversion, and the frontend gets what it expects.
Convert at the fetch layer. A small transform on incoming API responses (camelcase-keys on npm does it recursively in one line) keeps the conversion logic in one place on the frontend. Every response gets normalised before it touches application code.
Choose one and apply it consistently. Some teams use snake_case throughout: Python backend, SQL database, and JavaScript frontend. Unorthodox, but internally consistent. It works if the whole team agrees and linters enforce it.
The wrong approach: ignore the mismatch and mix conventions within the same file. You end up with response.user_name next to const userName = response.user_name, which makes every reader pause.
If you need to manually convert between the two (debugging a response, reformatting a config file), the snake_case converter and camelCase converter handle it without fuss.
Which is more readable?
There's a 2009 study by Binkley et al. that measured snake_case vs camelCase recognition speed on 135 subjects. snake_case identifiers were recognised faster initially. camelCase users caught up with practice, but familiarity with camelCase didn't fully close the gap on unfamiliar identifiers.
Personally, I find snake_case easier to read because underscores behave like spaces: get_order_total reads as a phrase, while getOrderTotal requires a brief parsing step. The tradeoff is characters: maximum_retry_count is three characters longer than maxRetryCount, and in a verbose language that adds up.
That said, the readability argument doesn't settle the question. You're choosing for a language that already has an established convention and a community that follows it. A Python codebase in camelCase is technically valid; it's also immediately jarring to every Python developer who reads it. The convention isn't just style; it's how the whole ecosystem communicates.
Enforcing your convention
Agreeing on a convention is only half the job. Something has to catch violations before they reach code review.
Python: pep8-naming is a flake8 plugin that flags naming violations: N802 for function names that should be snake_case, N801 for class names that should be PascalCase. Add it to CI and the "I forgot" excuse disappears.
JavaScript/TypeScript: ESLint's built-in camelcase rule flags non-camelCase identifiers. For finer control (different rules for destructuring, imports, and properties), @typescript-eslint/naming-convention handles it with full configuration.
Shared projects: .editorconfig at the repo root won't enforce naming, but it handles indentation, line endings, and charset uniformly across editors and languages. It removes a whole category of "but mine looks different" from code review, keeping focus on logic rather than formatting.
FAQ
Does Python use snake_case or camelCase?
Python uses snake_case for variables, functions, method names, module names, and file names. Classes use PascalCase. Constants use SCREAMING_SNAKE_CASE. This is specified in PEP 8 and enforced by most Python linters via the pep8-naming plugin for flake8.
Does JavaScript use snake_case or camelCase?
JavaScript uses camelCase for variables and functions, PascalCase for classes and constructors, and SCREAMING_SNAKE_CASE for constants. This is consistent across Google's, Airbnb's, and the TypeScript team's style guides. ESLint's camelcase rule enforces it automatically.
Should JSON APIs use snake_case or camelCase?
If your consumers are JavaScript applications, camelCase avoids transformation overhead on both sides. If your consumers are Python services, snake_case is more natural. When the stack is mixed, convert at the serializer (backend) or at the fetch layer (frontend). Don't leave it to whoever happens to write the next endpoint.
Why does PEP 8 choose snake_case over camelCase?
PEP 8 doesn't give an explicit reason, but it reflects Python's broader preference for readability over brevity. Guido van Rossum has noted that code is read far more often than it's written. snake_case identifiers are easier to read without training: they look like words separated by spaces, which is how most people already process text.